i-Tree Buffer
(Technical support is not available for this tool. If you have questions about this tool, please contact both i-Tree Support and Dr. Ted Endreny.)
Highlights
- The i-Tree Buffer model simulates how watershed properties influence the spatial distribution of nonpoint source runoff that become pollutant loads into receiving waters.
- Export coefficients generally assume that pollutant loading is the same throughout an area. i-Tree Buffer uses state-of-the-art export coefficients which are local to HUC8s and specific to Land Uses (based on the work of White et al. (2015)), and i-Tree Buffer identifies how pollutant loading is likely to vary within a watershed based on likelihoods of runoff generation and buffering capacity.
- i-Tree Buffer provides managers with a tool to rapidly visualize, rank, and investigate the landscape areas most likely responsible for large pollutant loads.
- Inputs include: a) watershed elevation, b) land cover and impervious cover, c) soil hydrological properties, and d) pollutant export coefficients specific to the watershed and land use.
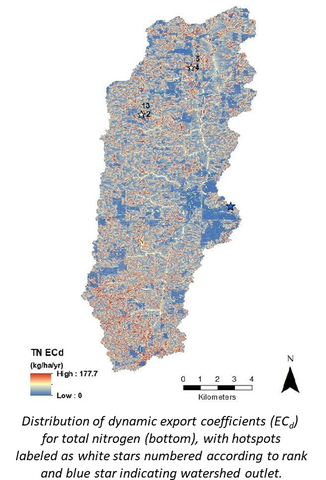
- Outputs include: a) maps of nonpoint source runoff loading hotspots for the pollutants of total suspended solids (TSS), total nitrogen (TN), and total phosphorus (TP), b) maps of nonpoint source runoff index likelihoods, and c) maps of pollutant buffering index likelihoods.
Description
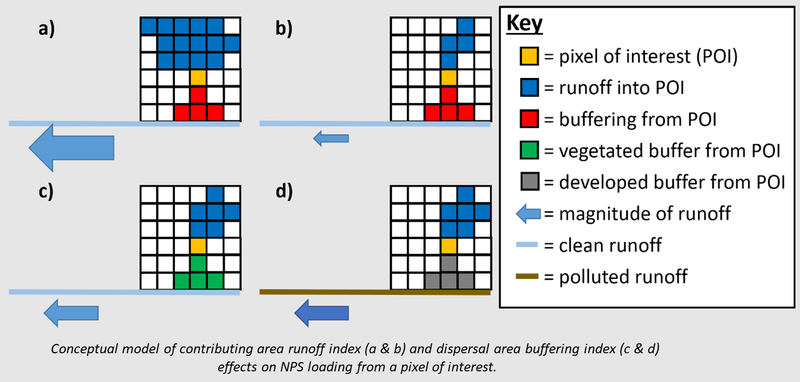
i-Tree Buffer model is software based on the contributing area - dispersal area (CADA) nonpoint source runoff model described by Stephan & Endreny (2016). For each pixel in a watershed, the Buffer model uses the land cover type to get an export coefficient value, then analyzes the upslope contributing area to quantify the likelihood for water to accumulate by surface and subsurface pathways and generate runoff from that pixel, then analyzes the downslope dispersal area to quantify the likelihood for surface and subsurface runoff to undergo pollutant buffering. The pixel's upslope contributing area data are converted into a runoff index likelihood, and the downslope dispersal area data are converted into a buffer index likelihood which are used to spatially weight the export coefficients.
This model has been setup for the i-Tree Research Suite to run efficient analysis anywhere in the country. However, to enable that breadth and quality of simulations, a large (>100GB) dataset of inputs is currently required to use this tool. In the model link below, metadata describing that large dataset is included in /Constants/ConstantsMetaData.xlsx. A copy of this large dataset is available for download as a split 7-Zip archive. In the future, i-Tree Buffer is intended to be integrated as a model within the HydroPlus framework, using web-based inputs rather than a large local dataset, to be more accessible to users.
While free technical support is not available for Research Suite tools including i-Tree Buffer, users interested in paid consultations or custom runs with the Buffer model are invited to contact info@itreetools.org.
Links
- Latest i-Tree Buffer (.py) script and files (revision 49)
- Input data for U.S. Great Lakes region (as a split 7-Zip archive)
- To extract data from this split archive, download all parts to the same directory, then use 7-Zip to extract the first part file. As a result the entire split archive will be extracted.